Cluster Placement Group
A Cluster Placement Group positions all instances in close proximity within the same availability zone—and often on the same rack. This configuration minimizes network latency and maximizes network throughput, making it highly suitable for high-performance computing applications as well as big data and analytics workloads.Using a Cluster Placement Group can significantly improve communication speeds between instances when they are tightly coupled.
Partition Placement Group
Partition Placement Groups distribute instances across distinct logical partitions. Each partition has its own set of racks with independent network and power sources. This design minimizes risk because a failure (such as a given hardware malfunction or power outage) in one partition does not impact the others. Partition Placement Groups are an excellent choice for distributed or replicated workloads, including Hadoop-based applications.The separation provided by partitions ensures that a failure in one partition does not cascade to affect the entire application.
Spread Placement Group
Spread Placement Groups are designed to mitigate correlated failures by allocating each instance its own dedicated hardware along with isolated racks and power sources. With each instance operating on separate underlying infrastructure, this option is ideal for a small number of critical instances that require maximum isolation.Spread Placement Groups should be used when critical workloads demand strict isolation from potential hardware failures.
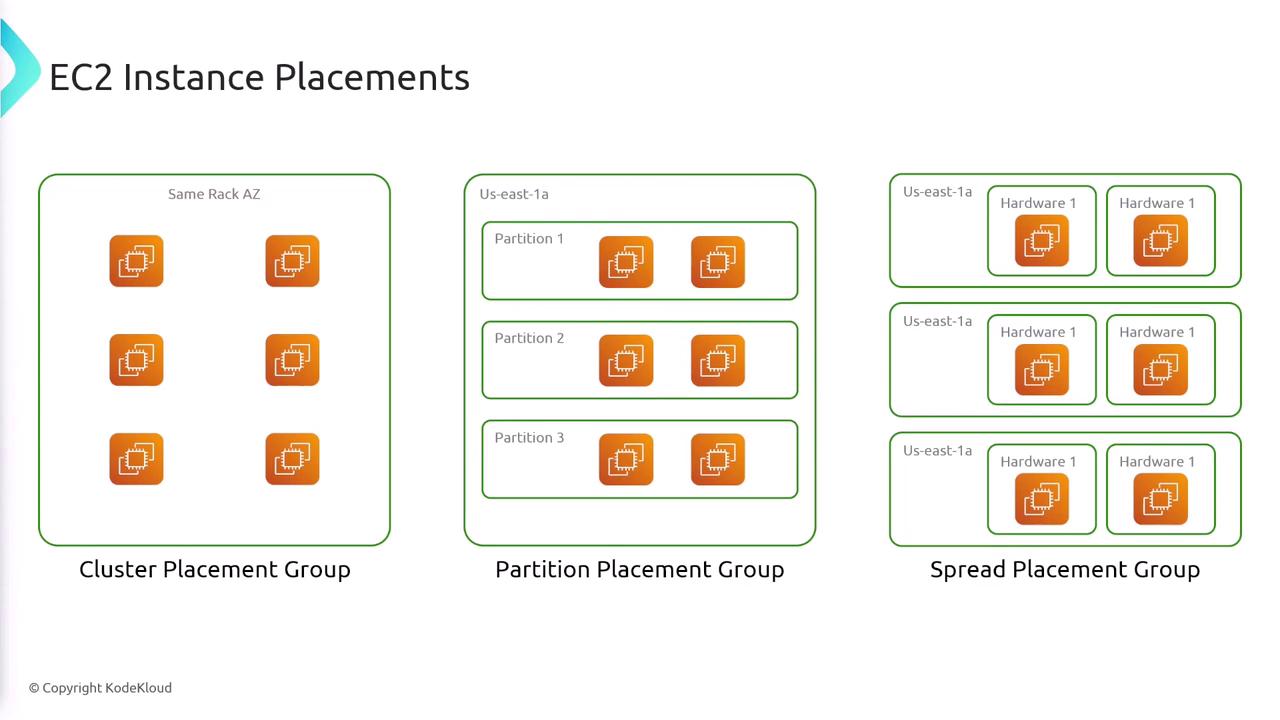
Key Comparisons
The main difference between partition and spread placement groups is in how instances share hardware resources:- In a Partition Placement Group, multiple instances can coexist within the same logical partition, though they do not share the underlying hardware across different partitions.
- In a Spread Placement Group, every instance operates on dedicated hardware, ensuring complete isolation between them.