Single-Node Setup
Imagine you have Elasticsearch installed on a single machine that stores logs. This single-node setup comprises specific hardware configurations such as memory, CPU, disk, and network. Although suitable for development and testing, this configuration is not ideal for production due to its limited scalability and redundancy.
A single-node environment is a great starting point for learning and experimentation, but production systems require a more robust solution to ensure high availability and performance.
Transitioning to a Cluster
As your requirements grow, scaling Elasticsearch by deploying it as a cluster—a group of interconnected nodes—is the preferred approach. When Elasticsearch runs on multiple nodes, they work together seamlessly, whether within a single availability zone or distributed across multiple zones. For example, having nodes in both zone 1A and zone 1B improves disaster recovery and overall system performance. In a cluster, not all nodes have the same roles. Consider a cluster consisting of five nodes: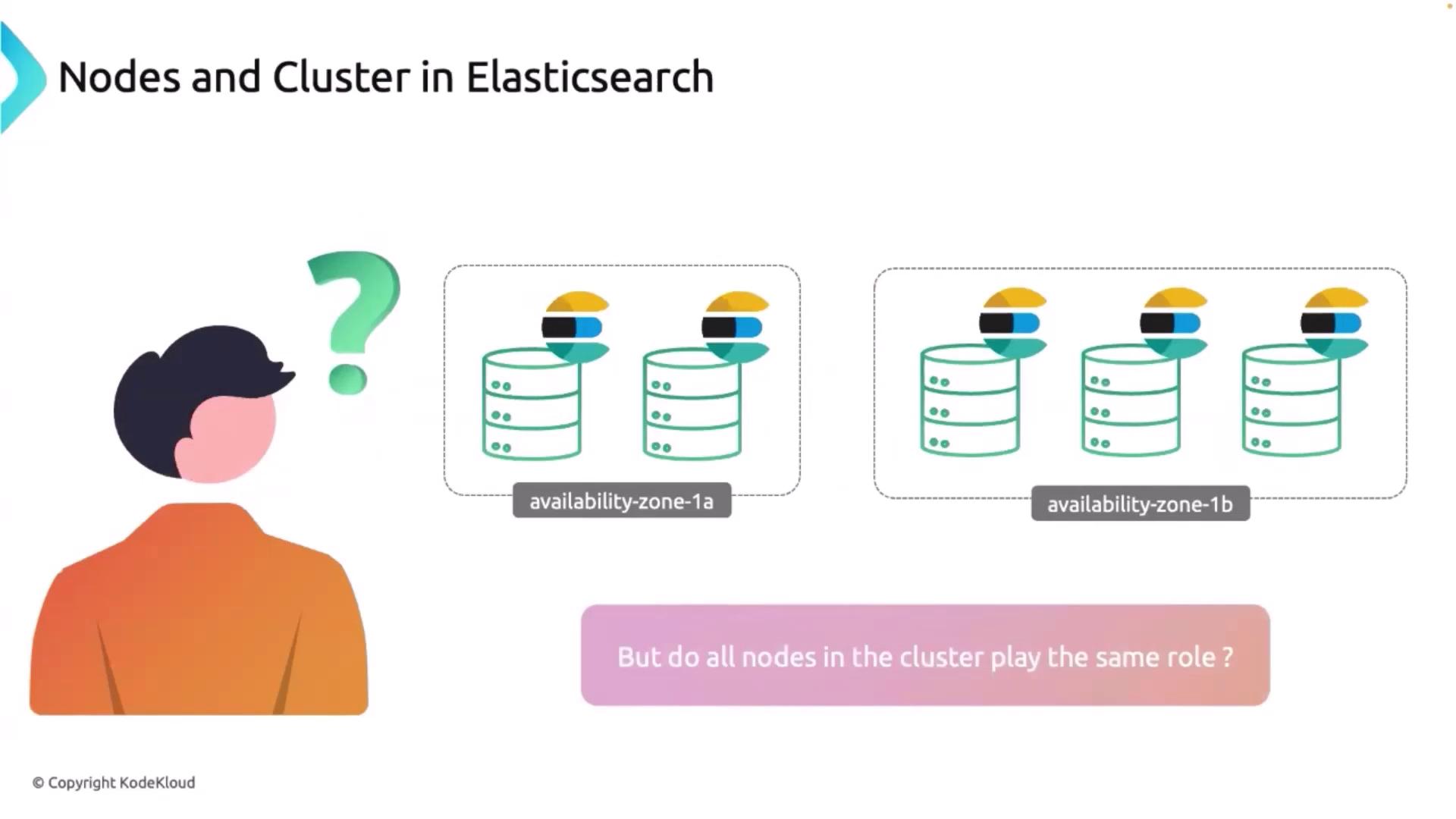
Key Features of Elasticsearch Clusters
Elasticsearch clusters offer several advantages designed to simplify data management and enhance performance:- Unified Namespace: The cluster creates a single view of all your data. Despite being distributed across multiple nodes, data can be queried as if stored in one location.
- High Availability: The system uses replica shards, which are copies of primary shards, to ensure data remains available even if a node fails.
- Load Distribution: By dividing responsibilities across nodes, the cluster efficiently handles a high volume of data and queries.
- Fault Tolerance: Automatic detection and reassignment of node roles in the event of a failure minimizes downtime and prevents data loss.
In a multi-node setup, the abstraction provided by the unified namespace not only simplifies indexing and search operations but also reduces the complexity of managing several data sources.
Scalability of Elasticsearch Clusters
Scalability is at the heart of Elasticsearch’s design. The architecture allows you to scale horizontally—adding more nodes as needed to manage increasing volumes of data and user queries. The process of integrating new nodes into the cluster is seamless and does not require downtime, making it a perfect solution for evolving application requirements.
| Feature | Benefit | Example Use Case |
|---|---|---|
| Collection of Nodes | Distribute workload across multiple machines | High-traffic log analysis |
| Single Namespace | Simplify data querying and management | Centralized search across large datasets |
| Redundancy & High Availability | Ensure continuous service even during failures | Mission-critical applications with strict uptime SLAs |
| Scalability | Seamless expansion with added nodes | Rapid growth in data volume requiring quick resource scaling |
Ensure proper monitoring and resource planning when scaling your Elasticsearch cluster, as misconfigurations can lead to performance degradation or service interruptions.