
Why LLMs Require Context
Large language models are typically trained on data with a fixed cutoff date. As a result, they can’t natively answer questions about events or data emerging after that cutoff. For example:Ask ChatGPT about yesterday’s news, and it will respond that it has no knowledge beyond its training cutoff.To bridge this gap, production systems programmatically retrieve data—such as a paragraph from a recent article—and inject it into the prompt. This automation replaces manual copy–paste and ensures responses remain current.
Understanding and Preventing Hallucinations
When an LLM lacks sufficient information, it may generate plausible but incorrect or fabricated content, known as hallucination.
Hallucinations can mislead users and degrade trust in your application. Always supply accurate and verifiable context.
Core Components of a Contextual LLM Workflow
The following diagram outlines the key building blocks of a contextual LLM application: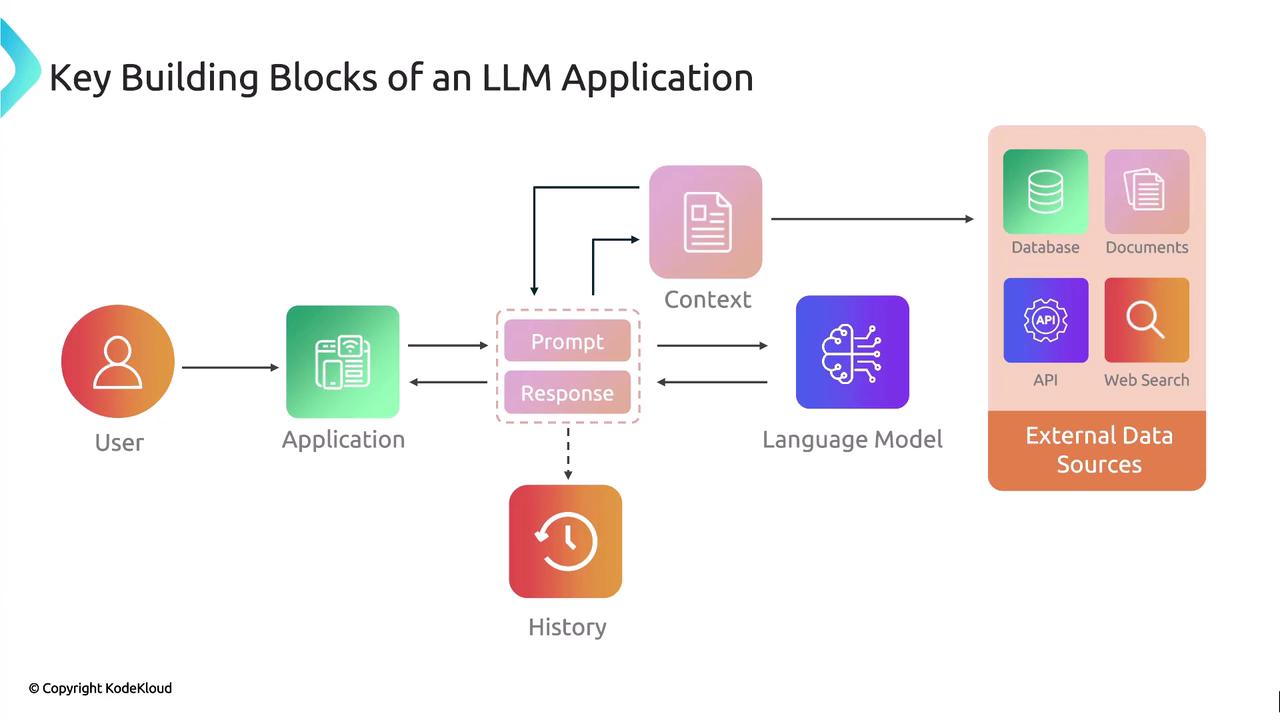
- User Input: The initial query or instruction.
- Context Retrieval: Fetching relevant data from external sources.
- Prompt Assembly: Combining user input, retrieved context, and any conversation history.
- Language Model: The LLM processes the assembled prompt.
- Response Delivery: The model’s output, grounded by the supplied context.
External Data Sources for Context
To ensure comprehensive coverage, LLM applications can pull from a variety of sources:
| Source Category | Examples | Usage |
|---|---|---|
| Structured | PostgreSQL, MySQL | SQL queries for transactional and tabular data |
| NoSQL | MongoDB, Cassandra | Flexible schemas for unstructured records |
| Vector Database | Chroma, Pinecone | Semantic search and similarity matching |
| Full-Text Documents | PDF, Word, HTML | Document embeddings and text extraction |
| Real-Time APIs | Stock quotes, Flight schedules | Live data for current events |
| Web Search | Custom scraping or search APIs | Aggregated information from multiple sites |
Choosing the right data source depends on your use case: transactional queries suit relational stores, while semantic retrieval demands a vector database.
Runtime Context Injection
At runtime, your application should:- Query each relevant data source.
- Extract and preprocess the results (e.g., chunking large documents).
- Integrate the processed information into the LLM’s prompt.
- Send the enriched prompt to the model for inference.