Tokenization
Tokenization is the first step in training a language model. In this process, a sentence is dissected into its individual elements, or tokens, which the model then converts into numerical representations. For instance, consider the sentence: “I heard a bird chirping in a tree.” Since the model operates on numbers rather than words, each word is assigned a unique numerical token. For example:- “I” might be represented as 1
- “heard” as 2
- “a” as 3
- “bird” as 4
- “chirping” as 5
- “in” as 6
- “a” (again) remains as 3
- “tree” as 7


Embeddings
Once the text has been tokenized, the next step is creating embeddings. Embeddings transform each token into a point in a multidimensional space, effectively capturing the semantic nuances of each word. In this space, words with similar meanings are positioned closer together. Consider the words “cat,” “dog,” “bird,” and “snake.” Despite all representing animals, “cat” and “dog” might be placed nearer each other in the embedding space due to their more common association as pets. The process assigns a set of numerical coordinates (or vector) to each word, which enables the model to determine semantic similarity based on their spatial relationships.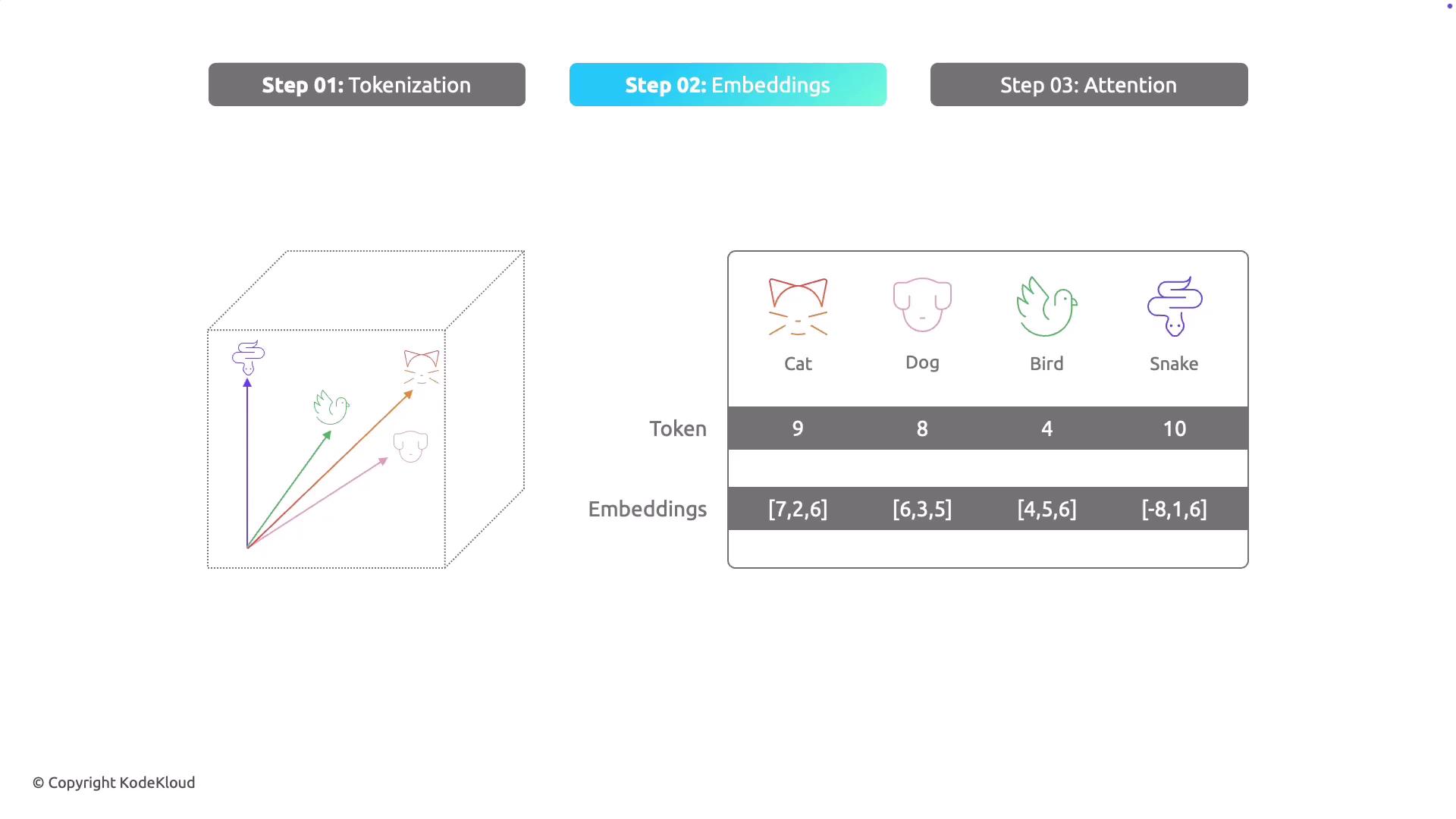
- “cat” as [7, 2, 6]
- “dog” as [6, 3, 5]
- “bird” as [4, 5, 6]
- “snake” as [-8, 1, 6]
Attention
The final critical step in language model training is the attention mechanism. Attention allows a model to focus on the most significant parts of a sentence when processing language. Rather than treating every token equally, the model assigns weights based on their relevance to the context or prediction task. Take the initial sentence “I heard a bird chirping in a tree.” If the task is to predict the word following “bird,” the model leverages the attention mechanism to focus more on words like “heard” and “bird”—which provide essential context—while giving less weight to tokens such as “I” or “in.” This targeted focus is key to generating accurate predictions; for example, it helps the model predict that “chirping” is a likely subsequent word after “bird.”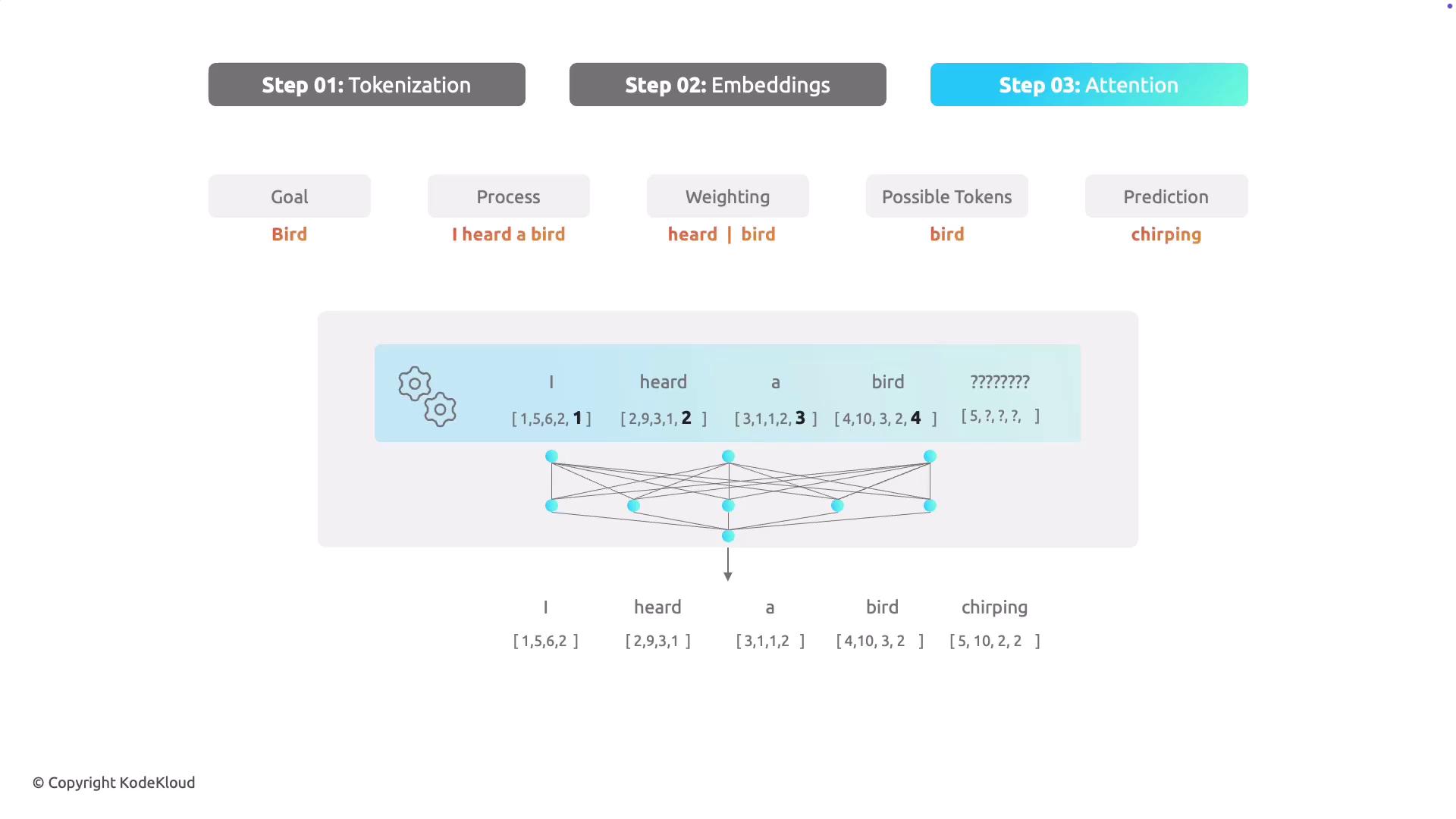
Attention mechanisms empower language models to prioritize contextually significant tokens, greatly enhancing their predictive capabilities.
Summary
To recap, training a language model involves these three pivotal steps:- Tokenization: Transforms sentences into tokens, with each word assigned a unique numerical value.
- Embeddings: Converts these tokens into vectors within a multidimensional space, thereby capturing semantic relationships between words.
- Attention: Enables the model to concentrate on the most relevant parts of a sentence, significantly improving context recognition and prediction accuracy.