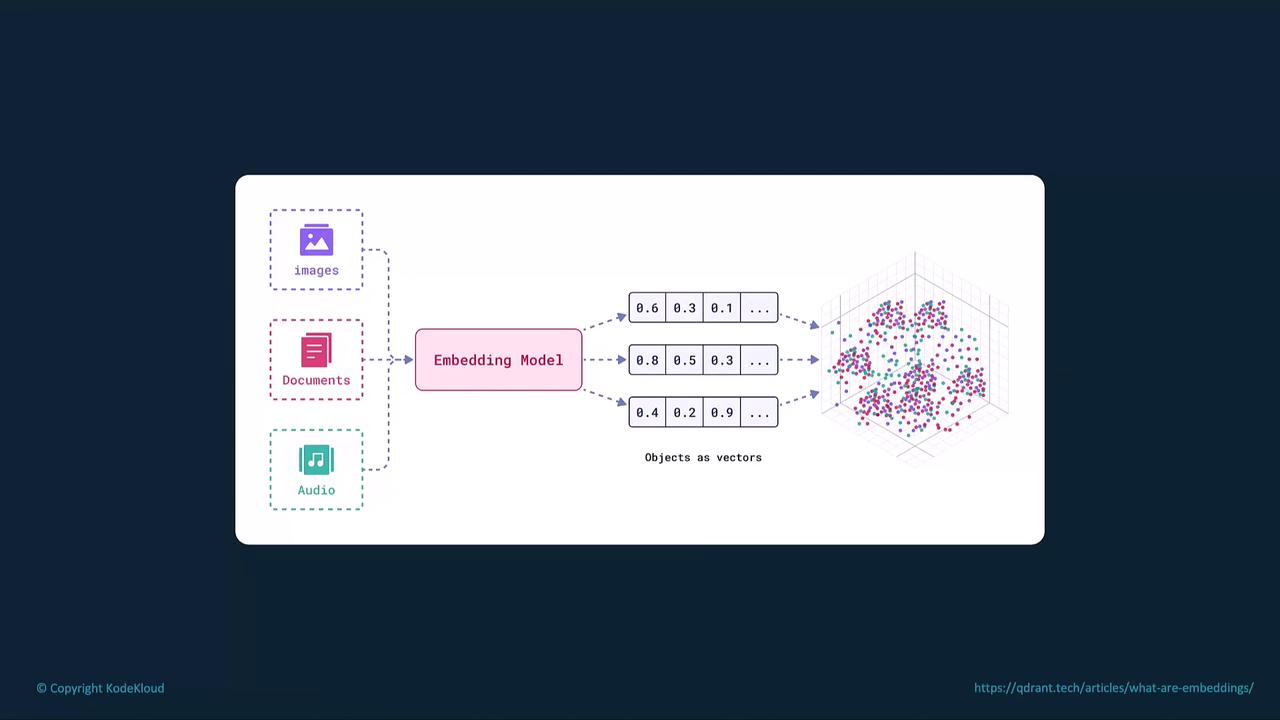
What Are Embeddings?
Embeddings are lists of floating-point numbers that capture the semantic features of text, images, or audio. The closer two vectors are in the embedding space, the more related their underlying data.
Common Applications of Embeddings
| Application | Description |
|---|---|
| Semantic Search | Rank results by relevance to a query across large corpora. |
| Clustering | Group similar texts (e.g., articles, feedback) automatically. |
| Recommendations | Suggest related items based on user or item vectors. |
| Anomaly Detection | Detect outliers by measuring low similarity scores. |
| Diversity Measurement | Analyze similarity distributions within a dataset. |
| Classification | Assign labels by comparing to prototype embeddings. |
Embedding distances are computed via metrics like cosine similarity or Euclidean distance. Choose the metric that best suits your task.
Why Embeddings Matter
- Semantic Understanding: Retrieve documents by meaning, not just keyword matches (e.g., “best smartphones” → “top mobile devices”).
- Contextual Search: Capture intent and context for more relevant search results.
- Personalization: Align recommendations with user preferences based on past interactions.
- Zero-Shot Learning: Predict unseen categories by positioning new labels near related known concepts.
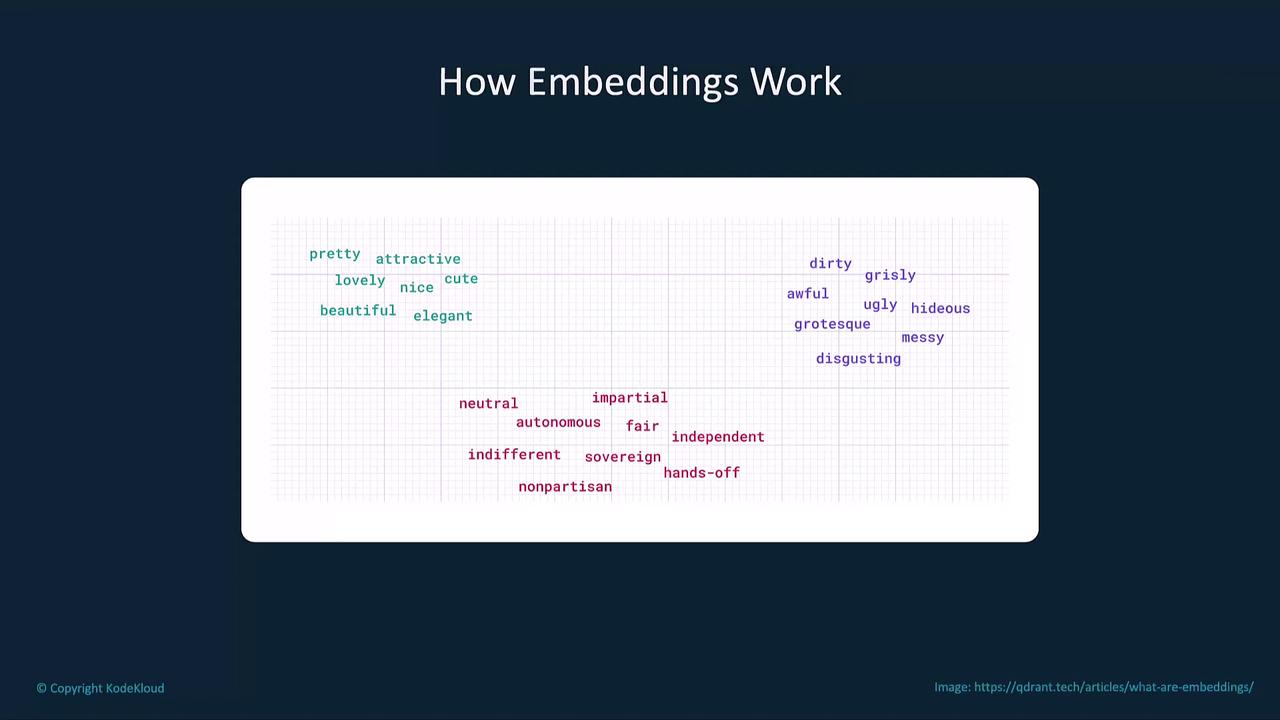
How Embeddings Work
- High-Dimensional Mapping: Each word, phrase, or document is converted into a vector in a multi-dimensional space.
- Clustering by Similarity: Semantically related items (e.g., “cat,” “feline”) cluster together.
- Separation of Unrelated Data: Dissimilar items (e.g., “cat,” “car”) lie far apart.
Generating Embeddings with the OpenAI API
Use the OpenAI Embeddings API to convert text into vectors:
Keep your API key secure. Avoid exposing it in public repositories or client-side code.
Key Use Cases
| Use Case | Description | Example |
|---|---|---|
| Semantic Search | Convert queries and documents into embeddings, then retrieve nearest items. | Building a FAQ chatbot that finds the most relevant answer by similarity. |
| Clustering | Group similar documents to detect topics or trends. | Organizing customer feedback into thematic clusters for analysis. |
| Recommendations | Compare item and user embeddings for personalized suggestions. | Suggesting products based on a user’s purchase history. |
| Zero-Shot Learning | Relate new labels to existing embeddings for classification without retraining. | Classifying support tickets into unseen categories. |
Example: Question Answering with Chat Models
This Python snippet embeds a Wikipedia article on the 2022 Winter Olympics and uses a chat model to answer a query:Best Practices

- Preprocess Text: Lowercase, remove punctuation, and filter stop words.
- Use Consistent Models: Stick to one embedding model per project for reliable comparisons.
- Leverage Pre-trained Embeddings: Save time and compute by using OpenAI’s optimized models.