- What is attention?
- How self-attention (scaled dot-product) works
- The power of multi-head attention
- Why attention drives transformer success
- Applications of attention in various tasks
- Challenges and limitations
1. Introduction to Attention
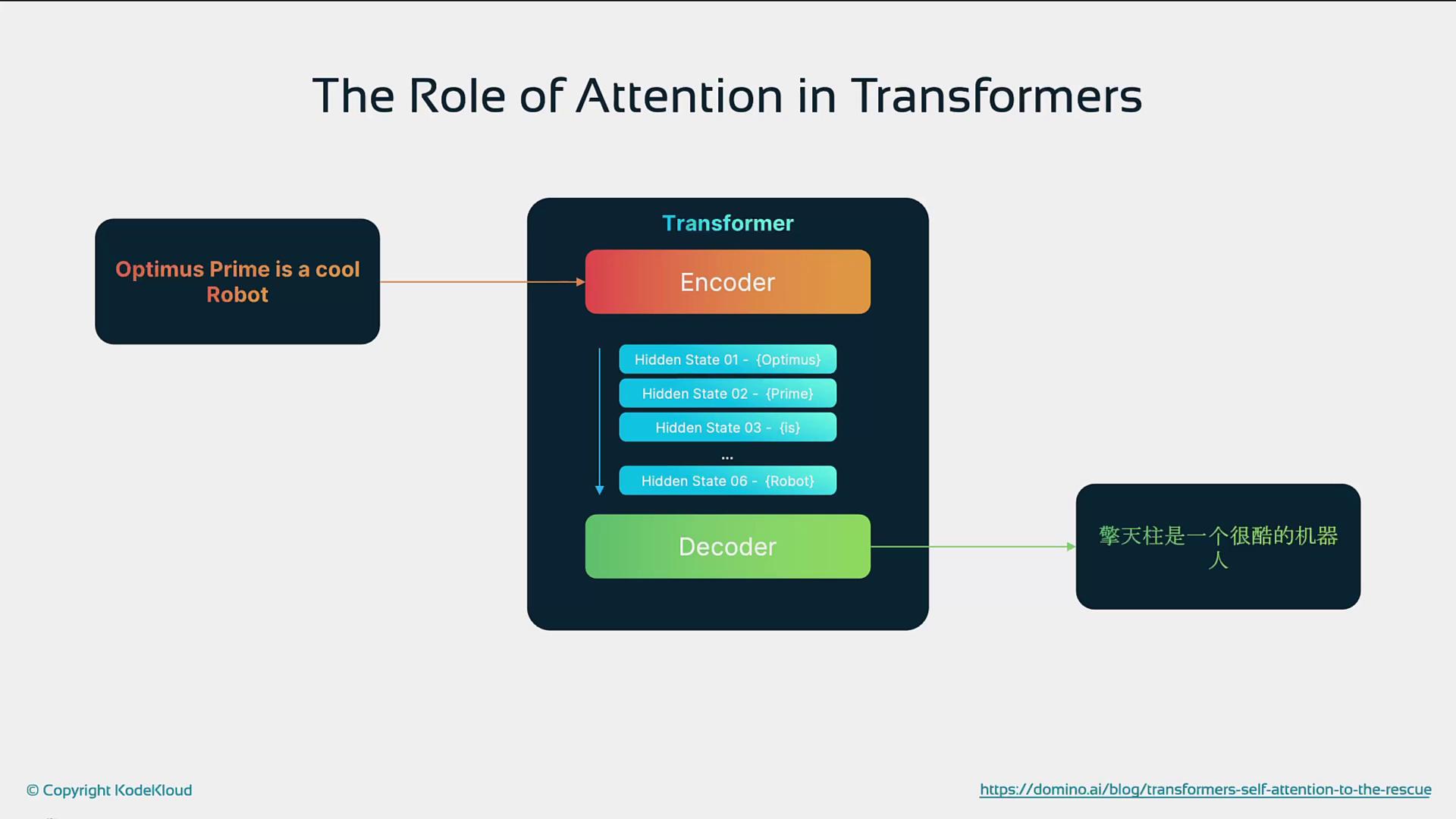
Attention lets a model assign dynamic importance to each token in a sequence. By projecting inputs into queries (Q), keys (K), and values (V), transformers compute scores that highlight the most relevant tokens when generating outputs.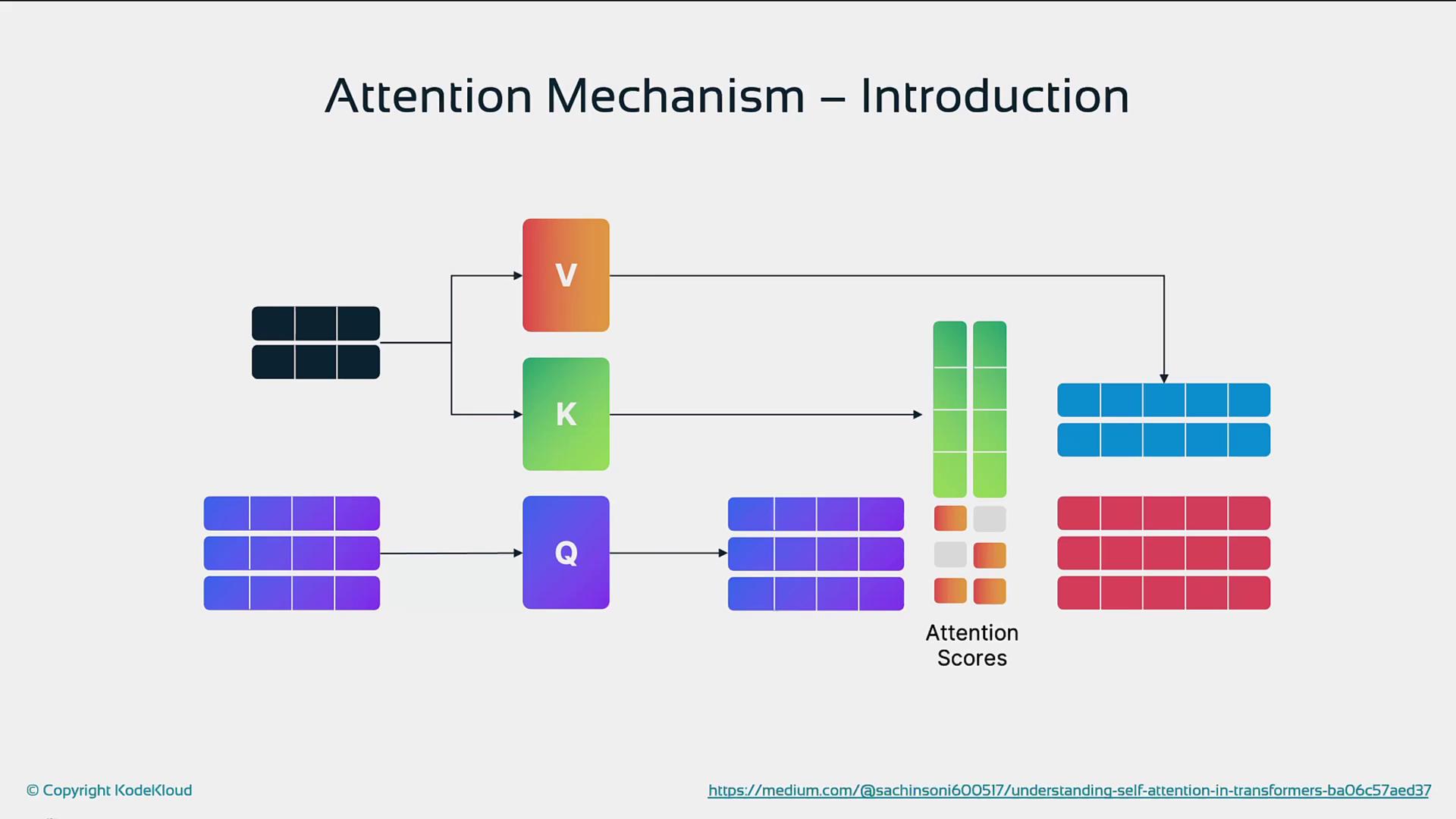
In “The cat sat on the mat,” the network may focus more on the relationship between “cat” and “sat” than “cat” and “mat.”

In transformers, every token attends to all others in parallel, eliminating the distance bias found in RNNs.
2. Self-Attention (Scaled Dot-Product)
Self-attention lets each token in a sequence weigh its relationship to every other token, capturing both local and long-range dependencies.Scaled Dot-Product Attention
-
Embeddings
Each token is mapped to a continuous vector. -
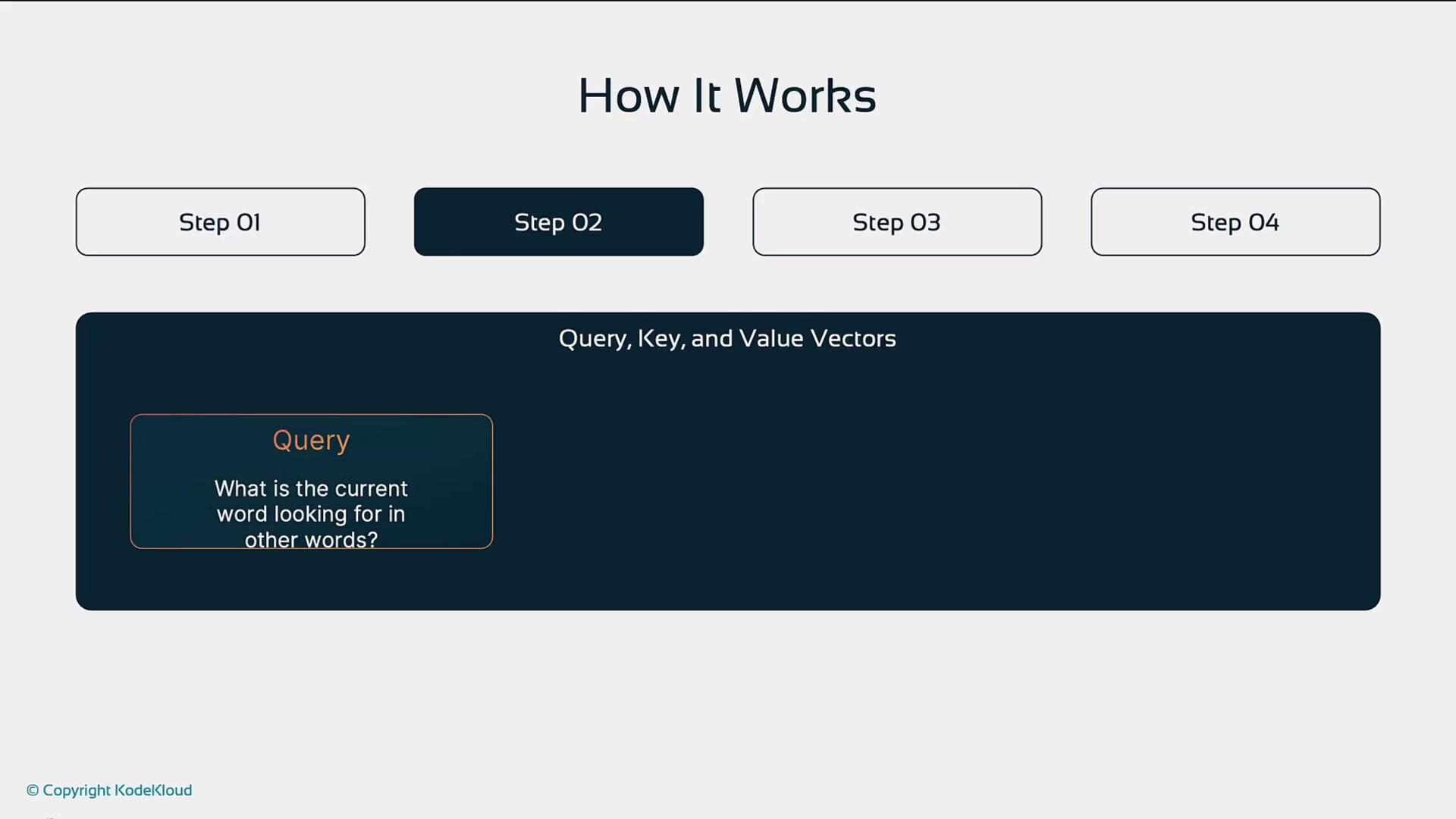
Query, Key, and Value
- Query (Q): What this token is looking for
- Key (K): What each token offers
- Value (V): The information to be aggregated
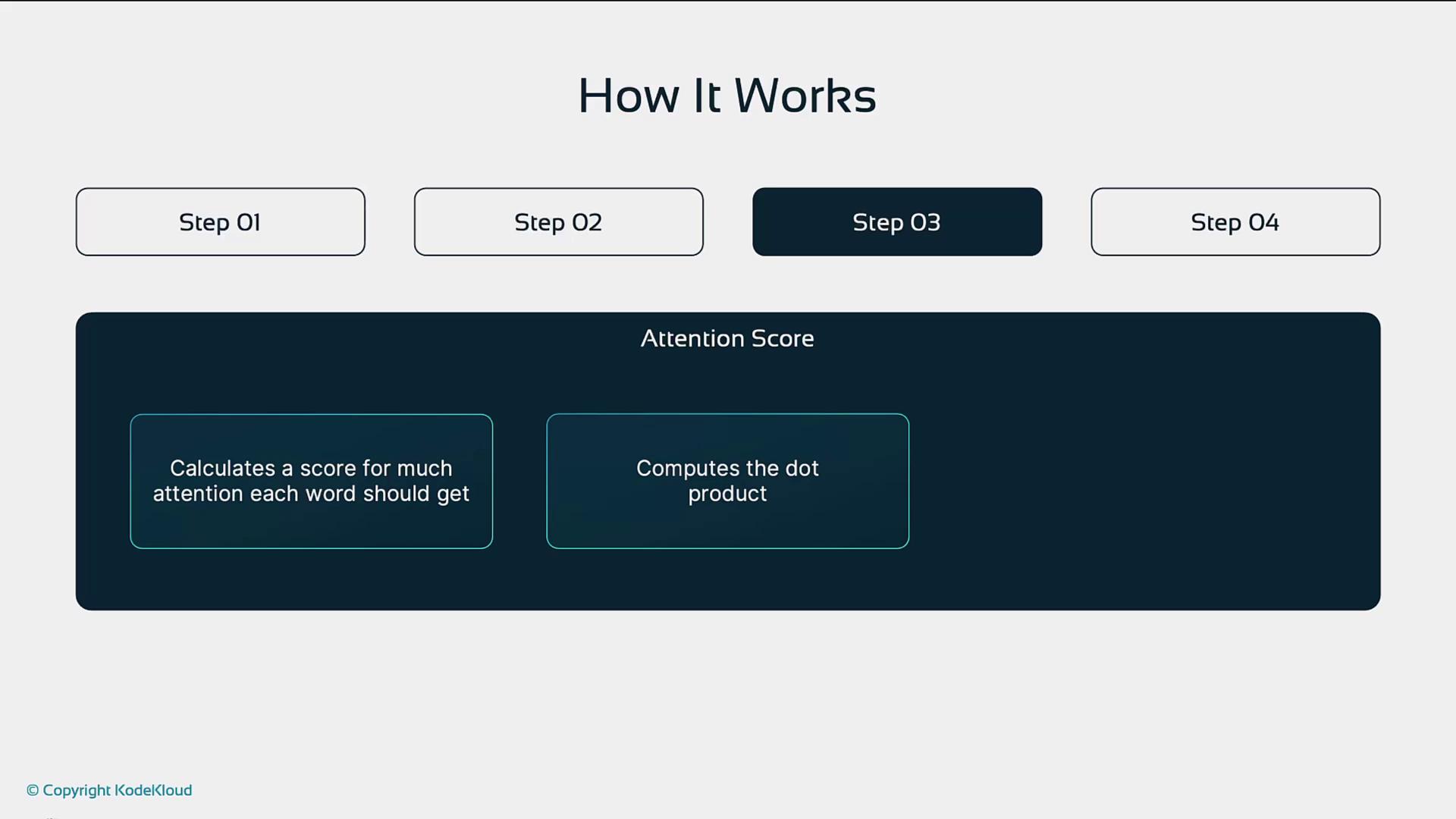
- Compute Attention Scores
Dot-product of Q and K, then scale and apply softmax:
- Weighted Sum
Use the softmax weights to blend V vectors into a context-aware representation.

3. Multi-Head Attention
Multi-head attention executes several self-attention operations in parallel, each with distinct linear projections of Q, K, and V. This diversity allows the model to capture different aspects of the sequence—such as syntax, semantics, or positional patterns—simultaneously.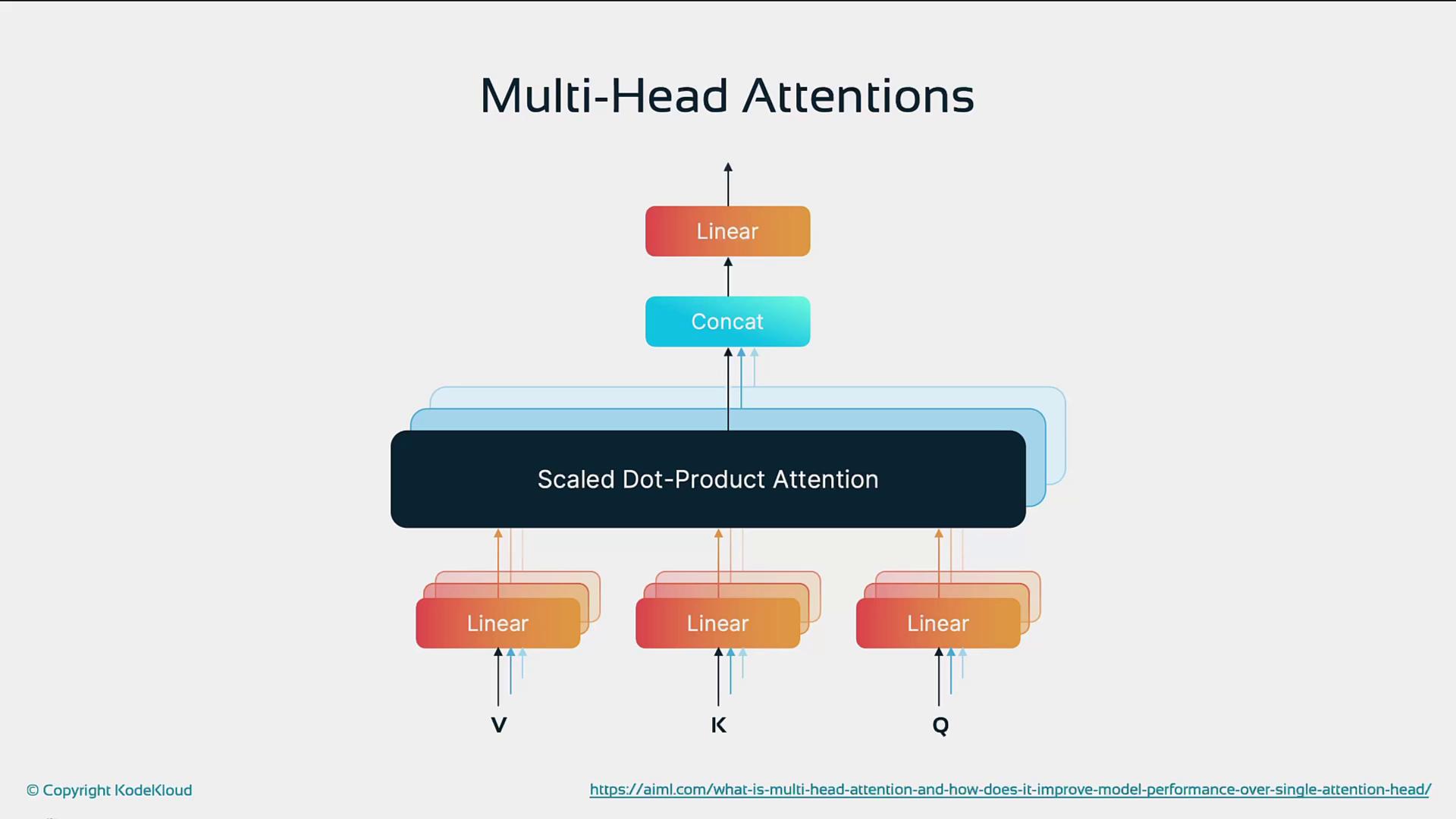
4. Role of Attention in Transformers
- Long-Range Dependencies
Direct token-to-token connections avoid the vanishing gradient issues of RNNs and LSTMs. - Parallel Processing
All tokens attend simultaneously, accelerating training and inference. - Scalability
Attention mechanisms scale with model size, enabling state-of-the-art systems like GPT-4 and DALL·E.
5. Attention in Various Tasks
Transformers have powered breakthroughs across modalities:| Task | Role of Attention | Example Model |
|---|---|---|
| Text Generation | Focuses on relevant history for next-token prediction | GPT-4 |
| Machine Translation | Aligns source and target tokens | TransformerBase |
| Vision Classification | Attends to image patches (edges, textures, objects) | ViT |
| Question Answering | Highlights context spans | BERT |
6. Challenges and Limitations
- Computational Cost
Attention’s quadratic complexity (O(n²)) can be prohibitive for very long sequences. - Interpretability
Attention weights hint at focus areas but don’t always clarify why decisions are made.
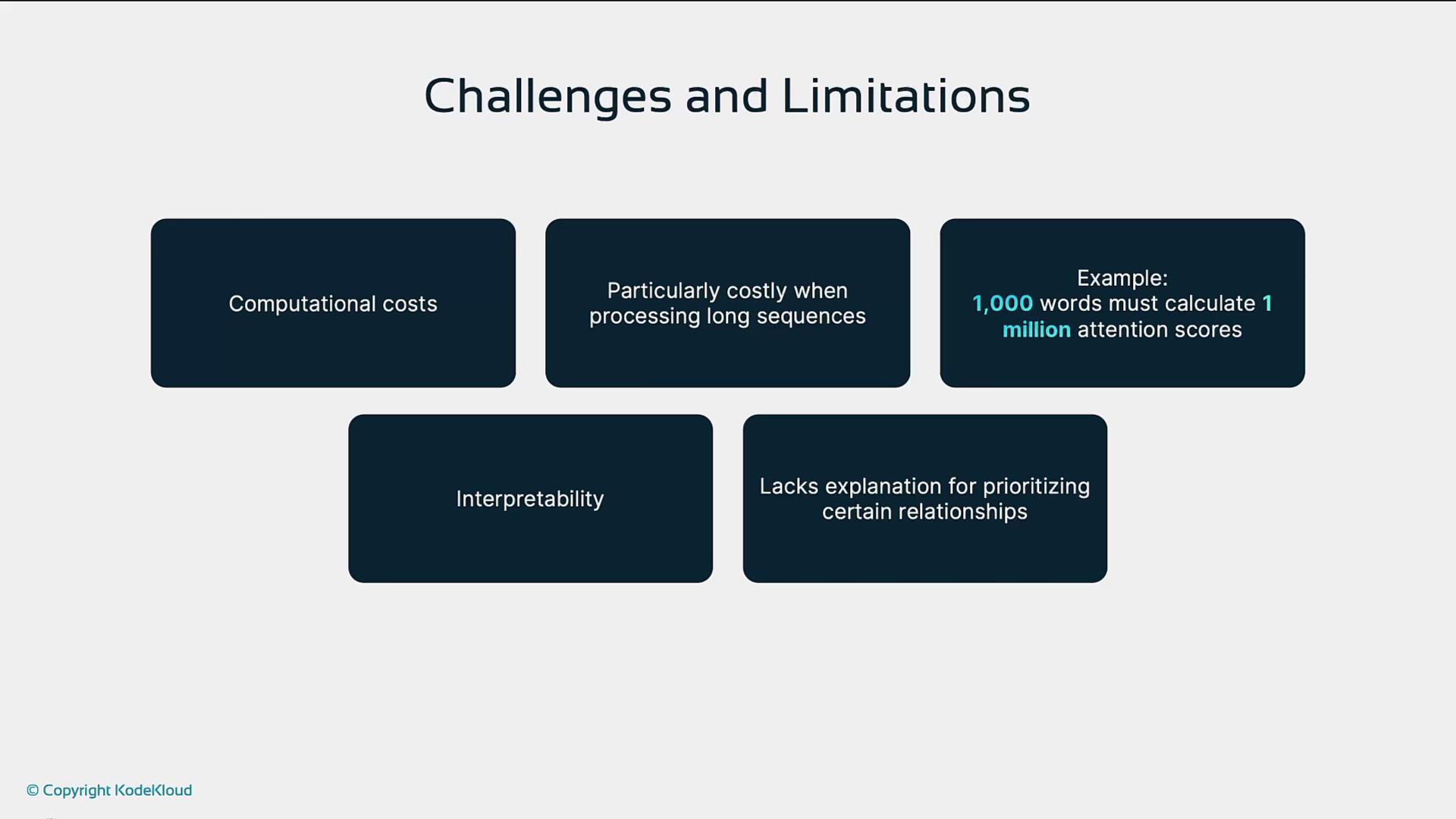
Quadratic scaling in sequence length can lead to memory bottlenecks. Consider sparse or linear attention variants for long inputs.