OpenAI’s API provides a rich set of model families and variants, each optimized for specific use cases—from code completion to conversational AI. Choosing the right model can help you balance performance, cost, and accuracy.
Model Families and Variants A model family groups related variants by their primary function. Each variant carries a version identifier reflecting its training improvements and feature set. Below is a high-level overview:
Model Family (Use Case) Variant Optimized For Davinci (Natural Language) text-davinci-002Instruction following text-davinci-003Advanced NLU and generation Codex (Code Completion) code-davinci-002Code autocomplete and synthesis GPT-3.5 (Chat & Completion) gpt-3.5-turboLow-latency chat and multi-turn support
GPT-3.5 Variants Overview The GPT-3.5 series balances capability and cost with varying token limits and data cutoffs:
Variant Max Tokens Training Data Through Primary Use Case text-davinci-0034,096 June 2021 Natural language tasks gpt-3.5-turbo4,096 September 2021 Chat-style interfaces
gpt-3.5-turbo is optimized for multi-turn dialogues and often delivers lower latency and cost for chat applications.
OpenAI continually refines these variants, improving response quality, speed, and cost-effectiveness.
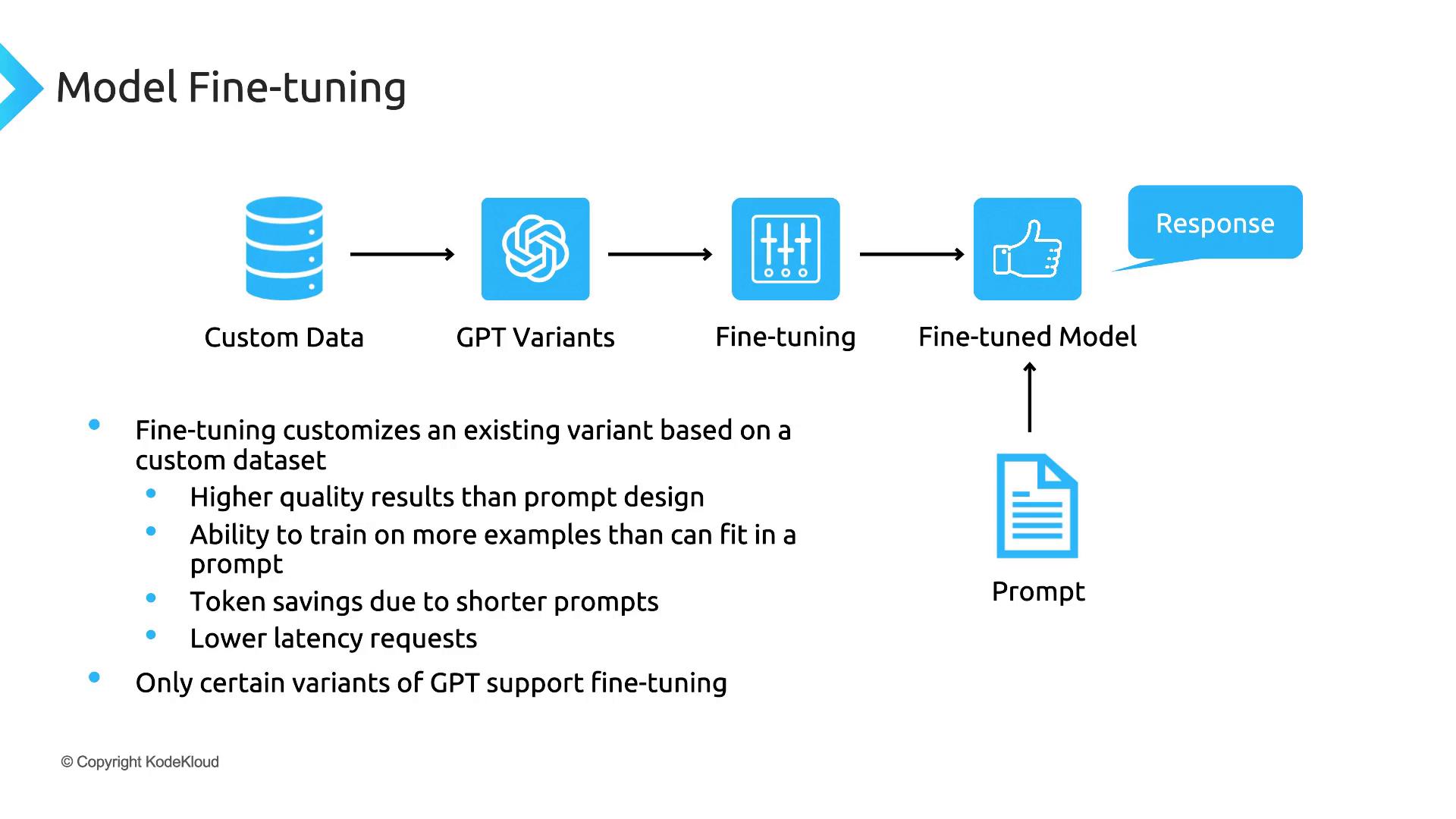
Fine-Tuning Models Fine-tuning allows you to customize a base model on your domain-specific dataset. Benefits include:
Domain-tailored responses with higher relevance
Shorter prompts, reducing token usage and cost
Faster inference, since context is baked into the model
Fine-Tuning Workflow
Format your dataset in JSONL with prompt–completion pairs.
Upload data and create a fine-tuning job via the CLI or API.
Monitor training, evaluate performance, and deploy your custom endpoint.
Ensure your training data is clean, balanced, and representative. Low-quality data can degrade performance.
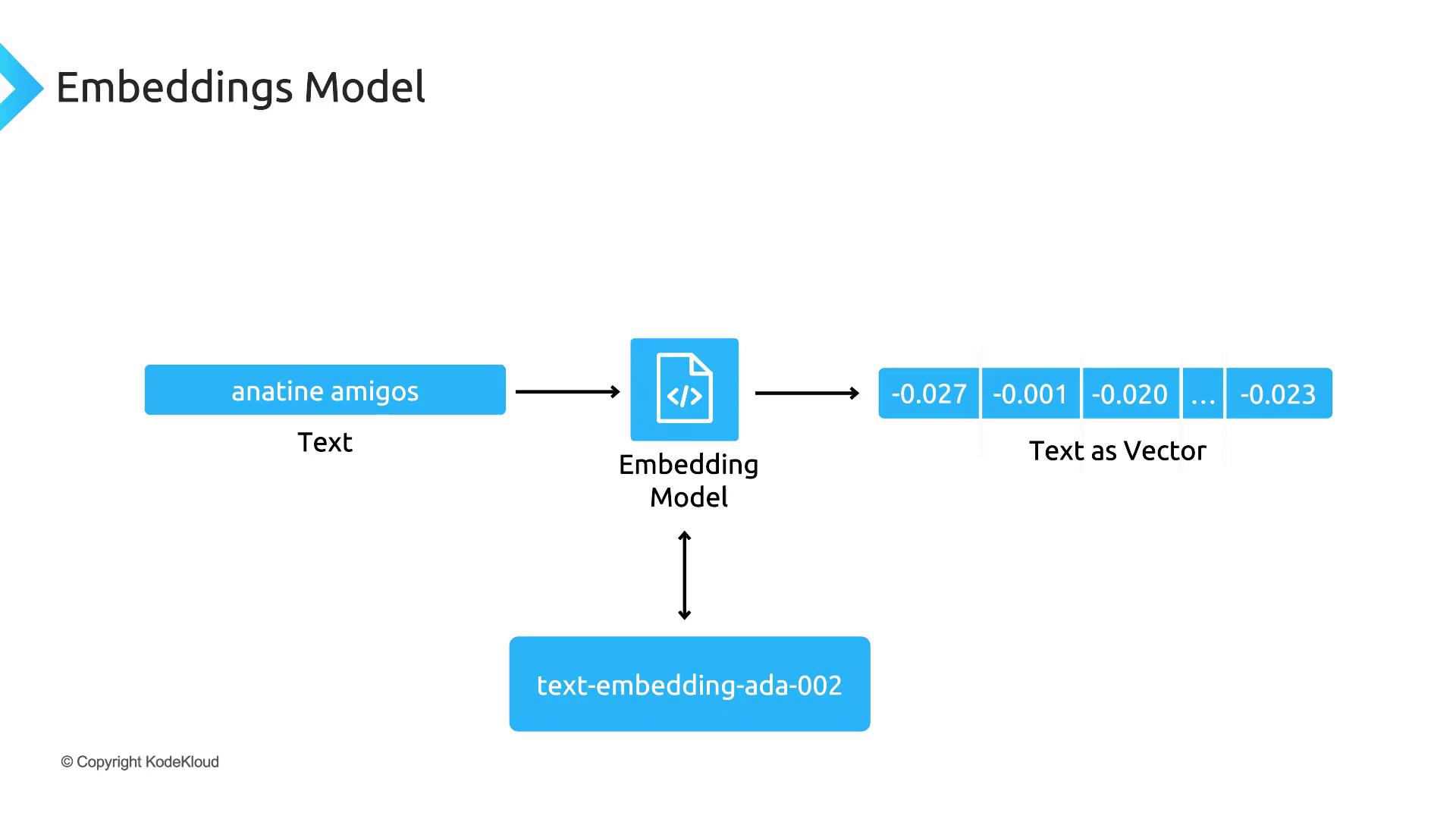
Embeddings and Semantic Search Embeddings convert text into vector representations for advanced applications:
Use Case Description Semantic Search Retrieve documents based on contextual meaning Recommendation Suggest similar content or products Entity Classification Categorize text into predefined classes
OpenAI’s text-embedding-ada-002 model generates high-quality embeddings at scale.
Other Model Families OpenAI’s ecosystem extends beyond GPT and Codex:
Links and References