Tuning inference parameters such as temperature, top-k sampling, top-p (nucleus) sampling, and presence/frequency penalties allows you to find the perfect balance between creativity and determinism. Experimenting with these settings is crucial for optimizing model performance.
Temperature
One essential inference parameter is the temperature, which controls the level of randomness in model outputs. A lower temperature results in more deterministic and accurate responses—ideal for applications in technical writing, healthcare, or legal settings where precision is paramount. Conversely, a higher temperature yields more creative and unpredictable responses by increasing the chance of selecting less likely words.
Top-K Sampling
Top-k sampling is another technique used to refine model output. With top-k sampling, the model restricts the token selection to the k most probable choices. For instance, if k is set to 50, the model considers only the top 50 tokens based on their probability scores. This method helps in narrowing down the output options to the most likely candidates.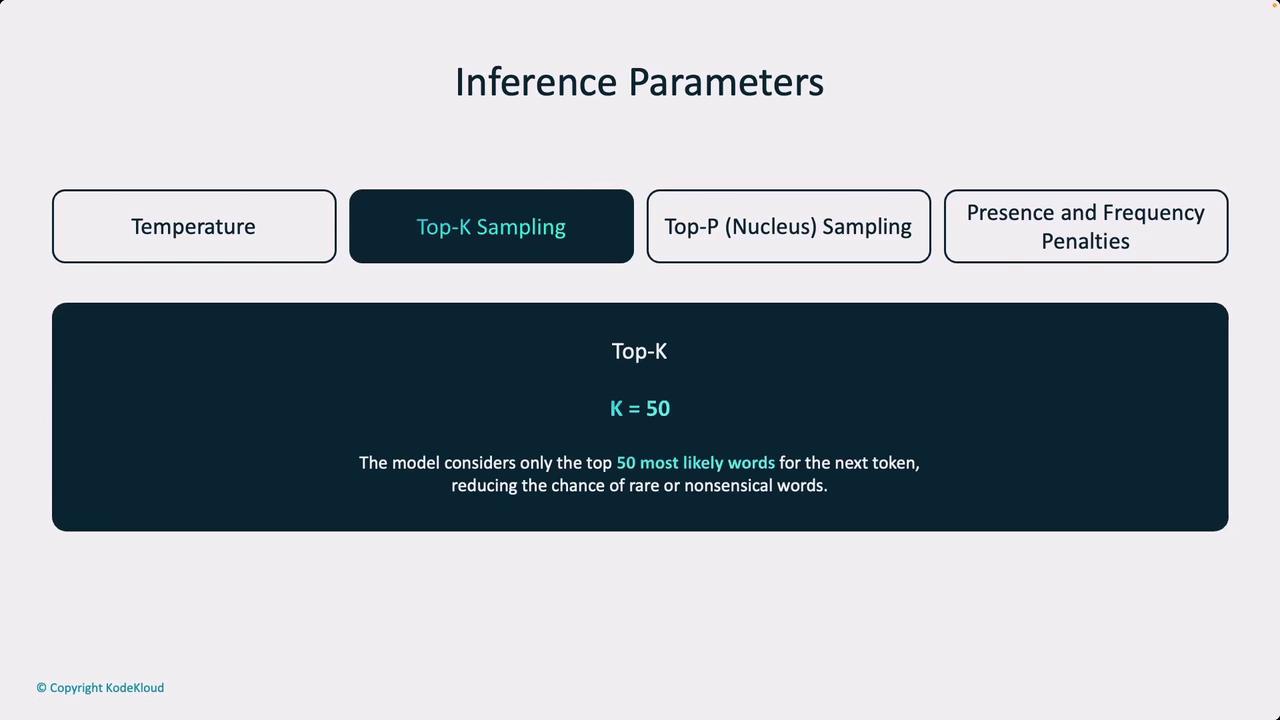
Top-P (Nucleus) Sampling
Another powerful technique is top-p sampling (also known as nucleus sampling). This method involves setting a cumulative probability threshold (for example, 0.9), ensuring that the model only considers the most probable tokens whose combined probability is up to the set value. Much like using a low temperature, top-p sampling encourages the model to focus on high-probability tokens, balancing diversity and coherence in the output.
Presence and Frequency Penalties
To enhance the novelty and prevent repetitive output, inference parameters also include presence and frequency penalties:- A presence penalty reduces the likelihood of previously occurring tokens, promoting new and varied content.
- A frequency penalty lowers the probability of tokens that have appeared frequently, further mitigating repetition.
